 Business
Business
Atribuímos a efetividade de nossos produtos ao conceito de Inteligência HuMachine – base do que chamamos de Cibersegurança de verdade. A essência dessa ideia é a fusão de três elementos fundamentais: big data, aprendizado de máquina e análise de especialistas. O que há por trás dessas palavras? Vamos explicar sem entrar mais do que o necessário nos detalhes técnicos.
Big data e inteligência de ameaças
O termo Big Data não deve ser interpretado ao pé da letra, ou seja, não se trata de uma quantidade absurda de informações armazenadas em algum lugar. Nem é uma base de dados, mas uma combinação de tecnologias que permitem processamento instantâneo de um grande volume de dados de modo a extrair inteligência de ameaças. Nesse caso, esses dados se relacionam com todos os objetos -verdadeiros, maliciosos ou potencialmente utilizáveis para fins danosos.
Para nosso perfil de atuação, pode-se entender como uma coleção vasta de elementos maliciosos. Segundo, inclui a Kaspersky Security Network, que entrega constantemente novos objetos suspeitos e dados complexos acerca de várias ciberameaças ao redor do mundo. Terceiro, Big Data refere-se a diversidade de ferramentas que processam os dados.
Coleção de objetos maliciosos
Nós nos dedicamos à segurança de computadores há mais de 20 anos, e ao longo desse tempo analisamos um grande número de objetos. As informações processadas são armazenadas em nosso banco de dados. Quando falamos de “objetos”, nos referimos não apenas a arquivos ou pedaços de códigos, mas também a endereços web, certificados, e registros de execução de arquivos para aplicações autênticas e mal-intencionadas. Todos esses dados são armazenados e categorizados não apenas em “perigosos” ou “seguros”, mas também com análise de suas relações com outros: de qual site aquele arquivo foi baixado, que outros também vieram dessa URL, e por aí vai.
Kaspersky Security Network (KSN)
KSN é o nosso serviço de segurança em nuvem. Uma de suas funções é bloquear rapidamente as ameaças mais recentes, protegendo nosso cliente o mais rapidamente possível. Ao mesmo tempo, permite a cada usuário participar do aumento da segurança global ao enviar metadados livres de identificação sobre ameaças para a nuvem. Estudamos cada informação detectada e adicionamos suas características ao nosso banco. Feito isso, nossos sistemas podem detectar precisamente não apenas aquela ameaça, mas também similares. Portanto, nossa coleta é atualizada em tempo real.
Ferramentas de categorização
Ferramentas de categorização são tecnologias internas que nos permitem processar informações coletadas e registrar o relacionamento entre objetos maliciosos supracitado.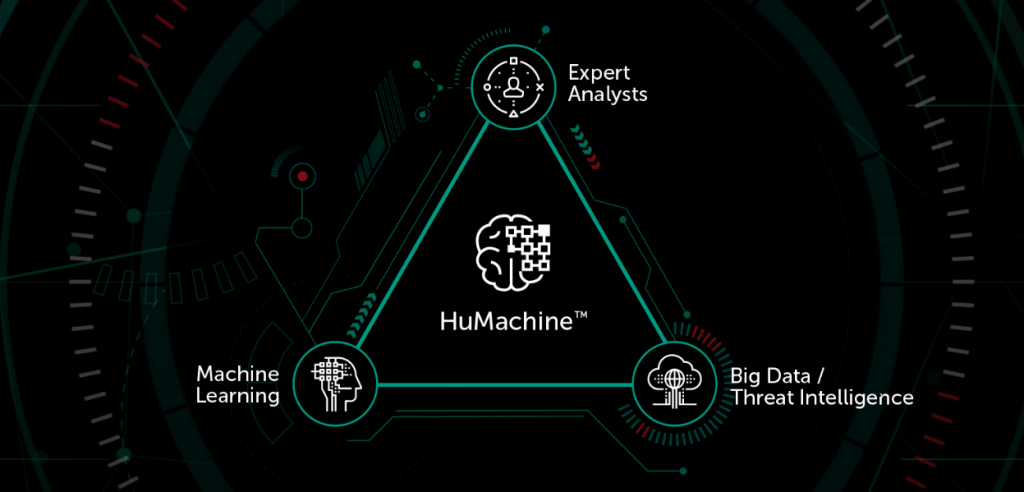
A tecnologia do aprendizado de máquina
Para delinear o que é aprendizado de máquina e como é usado na Kaspersky Lab precisaríamos de mais tempo. Devemos começar explicando que nossa metodologia é focada em uma abordagem multicamadas. Portanto, os algoritmos de aprendizado de máquina são usados em subsistemas diferentes em níveis distintos.
Detecção estática
Todos os dias nosso sistema recebe centenas de milhares de objetos (entre perigoso ou não) que precisam de análise e categorização imediata. Há mais de 10 anos, sabemos que não podemos lidar com esse volume sem automação. A primeira tarefa é entender se um arquivo suspeito se assemelha com um malicioso que já temos. Essa solução com aprendizado de máquina fica da seguinte forma: escrevemos um programa que analisa a coleção por inteiro e, quando um novo arquivo entra em cena, nossos analistas recebem as relações que ele pode ter com algum malicioso, por exemplo.
Logo ficou claro que saber se o objeto era similar a outros maliciosos não era suficiente. Precisávamos de tecnologia que permitisse ao sistema dar o veredito automaticamente. Por isso, construímos uma baseada em árvores de decisão. Treinada em nossa vasta coleção de objetos maliciosos, ela detectava, com base em um leque de critérios, combinações específicas das quais poderiam servir de indicadores que definem se um arquivo novo é perigoso ou não. Ao analisá-lo, um modelo matemático “pergunta” ao sistema de antivírus informações como as abaixo:
- O arquivo é maior que 100 kilobytes?
- Se sim, está comprimido?
- Se não, suas partes têm um nome que poderia ter sido escolhido por um ser humano ou não fazem sentido?
- Se foi o primeiro, então…
E a lista continua.
Depois de responder todas as perguntas, o antivírus recebe o veredito do modelo matemático. A decisão pode ser “o arquivo está limpo” ou “é perigoso”.
Modelos matemáticos comportamentais
Seguindo o princípio da segurança multicamadas, nossos modelos matemáticos também são usados para detecção dinâmica. Na verdade, pode-se analisar o comportamento de um arquivo executável logo que ele é colocado em ação. É possível construir e treinar um modelo de acordo com os mesmos princípios que os aplicados aos matemáticos em detecção estática, mas utilizar arquivos de registro como “material de treino”.
Contudo, há uma grande diferença. Em condições reais, não podemos esperar até o código terminar de executar. A decisão deve ser tomada depois de analisar uma quantidade mínima de ações. No momento, o piloto dessa tecnologia, baseado em aprendizado profundo, está exibindo resultados excelentes.
Especialistas humanos
Especialistas em aprendizado de máquina concordam que não importa o quanto um modelo matemático é eficiente, um ser humano sempre será capaz de passar por ele, especialmente se a pessoa em questão for criativa ao ponto de entender como a tecnologia funciona, ou ainda se há tempo suficiente para executar testes e experimentos diversos. É por isso que antes de mais nada, cada parte deve ser atualizável. Segundo, a infraestrutura precisa funcionar perfeitamente. Terceiro, um ser humano precisa supervisionar o robô. Preenchemos, todos esses requisitos.
Pesquisa Anti-Malware
Há uns 20 anos, nossa Time de pesquisa Anti-Malware (AMR na sigla em inglês) operava sem assistência de sistemas automáticos. Hoje, a maioria das ameaças são detectadas por sistemas especializados treinados por nossos pesquisadores. Em alguns casos, ele não é capaz de emitir um veredito inequívoco ou não consegue relacionar o objeto com qualquer família conhecida. Por isso, envia um aviso ao analista AMR de prontidão, fornecendo diversos indicadores que subsidiam a decisão final do analista.
Grupos de análise de métodos de detecção
Dentro do nosso AMR há um time de pesquisa específico chamado Grupo de Análise de Métodos de Detetcção, criado em 2007 especialmente para trabalhar com nossos sistemas de aprendizado de máquina. No momento, apenas o diretor do departamento é um analista de vírus experiente. Os outros são cientista de dados.
Time de Análises e Pesquisas Globais (GReAT).
Por último, mas não menos importante, vamos falar do nosso time de Análise e Pesquisas Globais (GreAT na sigla em inglês). Os pesquisadores dessa equipe investigam as ameaças mais complicadas: APTs, campanhas de ciberespionagem, surtos de malware, ransomware e tendências do submundo do cibercrime ao redor do mundo. Sua especialidade e técnicas únicas, ferramentas e esquemas de ciberataques permitem desenvolver novos métodos de proteção que possam impedir ataques ainda mais complexos.
Ainda não discutimos sequer metade das tecnologias e departamentos envolvidos no desenvolvimento de nossas soluções. Muitos outros especialistas e métodos diferentes do aprendizado de máquina trabalham juntos para protege-lo da melhor forma possível, queríamos dar ênfase ao princípio de Inteligência HuMachine.

 Dicas
Dicas