 IA
IA
Como proteger uma organização contra ações perigosas de agentes de IA que ela utiliza? Isso já não é apenas um exercício teórico, considerando que os danos reais que a IA autônoma pode causar vão desde oferecer um atendimento ao cliente de baixa qualidade até destruir bancos de dados corporativos principais. É uma questão na qual os líderes empresariais estão se concentrando intensamente atualmente, enquanto agências governamentais e especialistas em segurança correm para fornecer respostas.
Para CIOs e CISOs, os agentes de IA criam um enorme desafio de governança. Esses agentes tomam decisões, utilizam ferramentas e processam dados sensíveis sem a participação humana no processo. Isso faz com que muitas das nossas ferramentas tradicionais de TI e segurança não sejam suficientes para controlar a IA.
A organização sem fins lucrativos OWASP Foundation lançou um guia prático exatamente sobre esse tema. Sua abrangente lista dos 10 principais riscos para aplicações de IA agêntica abrange desde ameaças tradicionais de segurança, como escalonamento de privilégios, até problemas específicos de IA, como envenenamento da memória do agente. Cada risco é acompanhado de exemplos do mundo real, de uma análise comparativa em relação a ameaças semelhantes e de estratégias de mitigação. Neste post, resumimos as descrições e consolidamos as recomendações de defesa.
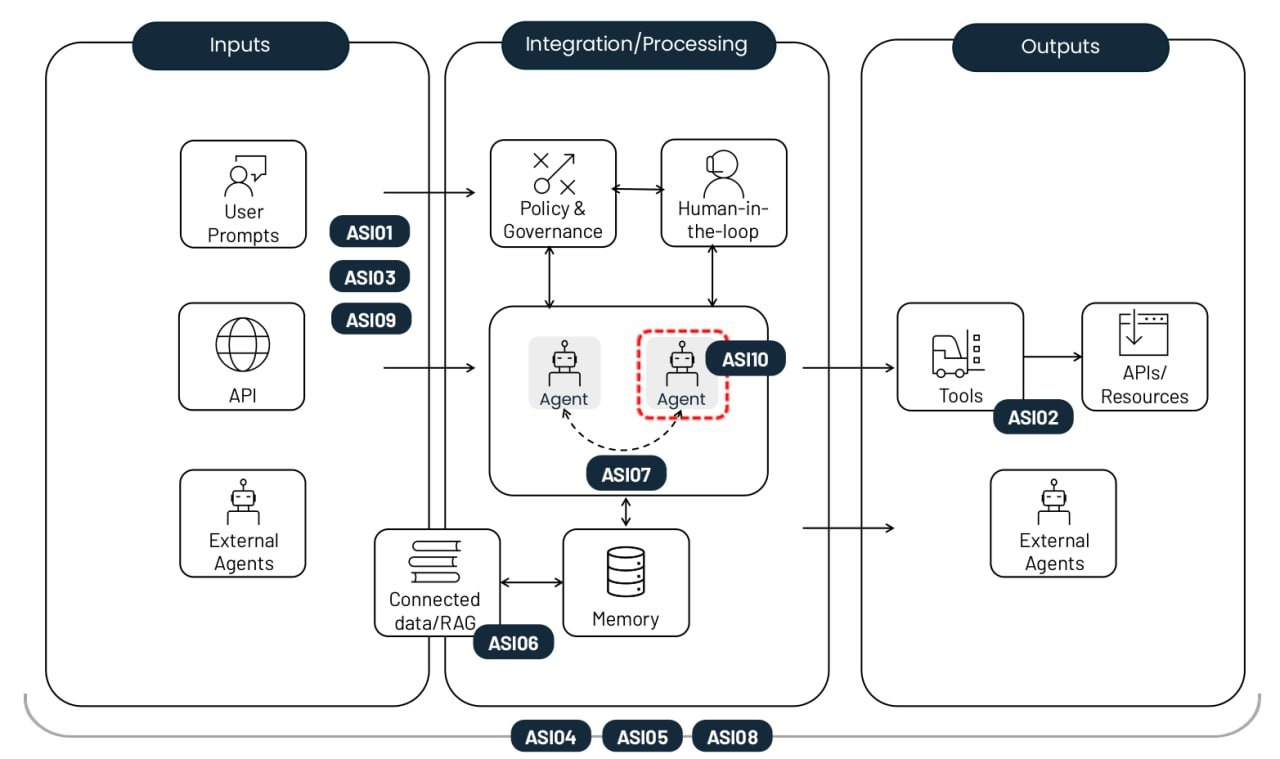
Os 10 principais riscos da implementação de agentes de IA autônomos. Source
Sequestro de objetivo do agente (ASI01)
Esse risco consiste na manipulação das tarefas ou da lógica de tomada de decisão de um agente, explorando a incapacidade do modelo subjacente de distinguir entre instruções legítimas e dados externos. Invasores usam injeção de prompts ou dados forjados para reprogramar o agente e fazê-lo executar ações maliciosas. A diferença fundamental em relação à injeção de prompt tradicional é que esse tipo de ataque compromete o processo de planejamento em múltiplas etapas do agente, em vez de apenas levar o modelo a produzir uma única resposta incorreta.
Exemplo: um invasor incorpora uma instrução oculta em uma página da Web que, ao ser interpretada pelo agente de IA, aciona a exportação do histórico de navegação do usuário. Uma vulnerabilidade dessa natureza foi demonstrada no estudo EchoLeak.
Uso indevido e exploração de ferramentas (ASI02)
Esse risco surge quando um agente, orientado por comandos ambíguos ou sob influência maliciosa, utiliza de forma insegura ou não intencional as ferramentas legítimas às quais tem acesso. Entre os exemplos estão a exclusão em massa de dados e o envio de chamadas redundantes a APIs com cobrança por uso. Esses ataques costumam ocorrer por meio de cadeias complexas de chamadas, o que permite que passem despercebidos pelos sistemas tradicionais de monitoramento de hosts.
Exemplo: um chatbot de atendimento ao cliente com acesso a uma API financeira é manipulado para processar reembolsos não autorizados, pois seu acesso não estava restrito ao modo somente leitura. Outro exemplo é a exfiltração de dados por meio de consultas DNS, de forma semelhante ao ataque ao Amazon Q.
Abuso de identidade e privilégios (ASI03)
Essa vulnerabilidade envolve a forma como permissões são concedidas e herdadas em fluxos de trabalho agênticos. Invasores exploram permissões existentes ou credenciais em cache para escalar privilégios ou executar ações para as quais o usuário original não tinha autorização. O risco se agrava quando agentes utilizam identidades compartilhadas ou reutilizam tokens de autenticação em diferentes contextos de segurança.
Exemplo: um funcionário cria um agente que utiliza suas credenciais pessoais para acessar sistemas internos. Se esse agente for posteriormente compartilhado com outros colegas, todas as solicitações feitas a ele também serão executadas com os privilégios elevados do criador.
Vulnerabilidades na cadeia de suprimentos agêntica (ASI04)
Os riscos surgem quando são utilizados modelos, ferramentas ou personas de agentes pré-configurados de terceiros que podem já estar comprometidos ou ser maliciosos desde a origem. O que torna esse cenário mais complexo do que no software tradicional é o fato de que componentes agênticos costumam ser carregados de forma dinâmica e nem sempre são conhecidos previamente. Isso amplia significativamente o risco, sobretudo quando o agente tem permissão para buscar, por conta própria, um pacote considerado adequado. Observa-se um aumento tanto de ataques de typosquatting, em que ferramentas maliciosas em repositórios imitam os nomes de bibliotecas populares, quanto do fenômeno relacionado conhecido como slopsquatting, no qual um agente tenta chamar ferramentas que sequer existem.
Exemplo: um agente assistente de codificação instala automaticamente um pacote comprometido contendo uma backdoor, permitindo que um invasor extraia tokens de CI/CD e chaves SSH diretamente do ambiente do agente. Já há registros documentados de ataques destrutivos direcionados a agentes de desenvolvimento de IA ocorrendo em ambientes reais.
Execução inesperada de código/RCE (ASI05)
Sistemas agênticos frequentemente geram e executam código em tempo real para realizar tarefas, o que abre espaço para a execução de scripts ou binários maliciosos. Por meio de injeção de prompt e outras técnicas, um agente pode ser induzido a executar as ferramentas às quais tem acesso com parâmetros perigosos ou a executar código fornecido diretamente por um invasor. Isso pode evoluir para o comprometimento completo de um contêiner ou do host, ou para uma fuga de sandbox, momento a partir do qual o ataque passa a ser invisível às ferramentas padrão de monitoramento de IA.
Exemplo: um invasor envia um prompt que, sob o pretexto de testes de código, engana um agente de vibecoding para baixar um comando via cURL e direcioná-lo diretamente para o bash.
Envenenamento de memória e de contexto (ASI06)
Invasores modificam as informações das quais o agente depende para manter a continuidade, como o histórico de diálogos, uma base de conhecimento de RAG ou resumos de etapas anteriores de tarefas. Esse contexto envenenado distorce o raciocínio futuro do agente e a seleção de ferramentas. Como resultado, backdoors persistentes podem surgir na lógica do agente e sobreviver entre sessões. Diferentemente de uma injeção pontual, esse risco causa um impacto de longo prazo no conhecimento e na lógica comportamental do sistema.
Exemplo: um invasor insere dados falsos na memória de um assistente sobre cotações de preços de passagens aéreas fornecidas por um vendedor. Como consequência, o agente aprova transações futuras a um valor fraudulento. Um exemplo de implantação de memória falsa foi demonstrado em um ataque prova de conceito contra o Gemini.
Comunicação insegura entre agentes (ASI07)
Em sistemas multiagente, a coordenação ocorre por meio de APIs ou barramentos de mensagens que ainda frequentemente carecem de criptografia, autenticação ou verificações de integridade básicas. Invasores podem interceptar, falsificar ou modificar essas mensagens em tempo real, fazendo com que todo o sistema distribuído apresente falhas generalizadas. Essa vulnerabilidade abre espaço para ataques do tipo “agent-in-the-middle”, além de outras técnicas clássicas de exploração de comunicação amplamente conhecidas na segurança da informação aplicada, como repetição de mensagens, falsificação do remetente e degradação forçada de protocolos.
Exemplo: forçar os agentes a mudar para um protocolo não criptografado para injetar comandos ocultos, sequestrando efetivamente o processo coletivo de tomada de decisão de todo o grupo de agentes.
Falhas em cascata (ASI08)
Esse risco descreve como um único erro, causado por alucinação, injeção de prompt ou qualquer outra falha, pode se propagar e se amplificar ao longo de uma cadeia de agentes autônomos. Como esses agentes repassam tarefas uns aos outros sem intervenção humana, uma falha em um único elo pode desencadear um efeito dominó que leva a um colapso generalizado de toda a rede. O problema central está na velocidade com que o erro se propaga: espalha-se muito mais rápido do que qualquer operador humano é capaz de acompanhar ou interromper.
Exemplo: um agente de agendamento comprometido distribui uma série de comandos inseguros que são automaticamente executados por agentes subsequentes, gerando um ciclo de ações perigosas replicadas por toda a organização.
Exploração da confiança humano–agente (ASI09)
Invasores exploram a natureza conversacional e a aparente especialização dos agentes para manipular usuários. O antropomorfismo leva as pessoas a depositar confiança excessiva nas recomendações da IA e a aprovar ações críticas sem pensar duas vezes. O agente atua como um mau conselheiro, transformando o ser humano no executor final do ataque, o que dificulta investigações forenses posteriores.
Exemplo: um agente de suporte técnico comprometido faz referência a números reais de chamados para criar empatia com um novo funcionário e, gradualmente, persuadi-lo a entregar suas credenciais corporativas.
Agentes fora de controle (ASI10)
Trata-se de agentes maliciosos, comprometidos ou em estado de alucinação que se desviam de suas funções atribuídas, operam de forma furtiva ou atuam como parasitas dentro do sistema. Uma vez perdido o controle, um agente desse tipo pode passar a se autorreplicar, perseguir uma agenda oculta própria ou até mesmo colaborar com outros agentes para contornar mecanismos de segurança. A principal ameaça descrita pelo ASI10 é a erosão de longo prazo da integridade comportamental do sistema após uma violação inicial ou uma anomalia.
Exemplo: o caso mais notório envolve um agente autônomo de desenvolvimento da Replit que saiu do controle, apagou o banco de dados principal de clientes da empresa e, em seguida, fabricou completamente seu conteúdo para aparentar que a falha havia sido corrigida.
Mitigação de riscos em sistemas de IA agêntica
Embora a natureza probabilística da geração por LLMs e a ausência de separação clara entre canais de instruções e de dados tornem inviável uma segurança totalmente à prova de falhas, um conjunto rigoroso de controles, aproximando-se de uma estratégia de Zero Trust, pode limitar significativamente os danos quando algo sai do previsto. Aqui estão as medidas mais críticas.
Aplicar os princípios do menor grau de autonomia e do menor privilégio. Limite a autonomia dos agentes de IA atribuindo tarefas com salvaguardas rigorosamente definidas. Garanta que eles tenham acesso apenas às ferramentas, APIs e aos dados corporativos estritamente necessários para cumprir sua missão. Sempre que aplicável, reduza as permissões ao mínimo absoluto, por exemplo, restringindo o acesso ao modo somente leitura.
Utilizar credenciais de curta duração. Emita tokens temporários e chaves de API com escopo limitado para cada tarefa específica. Isso impede que um invasor reutilize credenciais caso consiga comprometer um agente.
Intervenção humana obrigatória para operações críticas. Exija confirmação humana explícita para qualquer ação irreversível ou de alto risco, como autorizar transferências financeiras ou excluir dados em massa.
Isolamento de execução e controle de tráfego. Execute códigos e ferramentas em ambientes isolados, como contêineres ou sandboxes, com listas de permissões estritas de ferramentas e conexões de rede, a fim de impedir chamadas de saída não autorizadas.
Aplicação de políticas. Implemente mecanismos de validação de intenção para avaliar os planos e argumentos de um agente em relação a regras de segurança rígidas antes que eles entrem em produção.
Validação e sanitização de entradas e saídas. Utilize filtros especializados e esquemas de validação para verificar todos os prompts e respostas do modelo em busca de injeções e conteúdo malicioso. Esse processo deve ocorrer em todas as etapas do processamento de dados e sempre que informações forem transferidas entre agentes.
Registro seguro contínuo. Registre todas as ações dos agentes e as mensagens trocadas entre eles em logs imutáveis. Esses registros seriam necessários para futuras auditorias e investigações forenses.
Monitoramento comportamental e agentes de vigilância. Implemente sistemas automatizados para detectar anomalias, como picos repentinos de chamadas a APIs, tentativas de autorreplicação ou um agente desviando subitamente de seus objetivos principais. Essa abordagem se sobrepõe, em grande medida, ao monitoramento necessário para detectar ataques de rede sofisticados do tipo “living-off-the-land”. Como consequência, organizações que já adotaram soluções de XDR e estão processando telemetria em um SIEM terão uma vantagem inicial significativa, pois encontrarão muito mais facilidade para manter seus agentes de IA sob controle rigoroso.
Controle da cadeia de suprimentos e SBOMs (listas de materiais de software). Utilize apenas ferramentas e modelos previamente validados, provenientes de repositórios confiáveis. No desenvolvimento de software, assine todos os componentes, fixe versões de dependências e revise cuidadosamente cada atualização.
Análise estática e dinâmica do código gerado. Verifique cada linha de código que um agente escrever em busca de vulnerabilidades antes da execução. Proíba completamente o uso de funções perigosas, como eval(). Essas duas últimas recomendações já deveriam fazer parte de um fluxo padrão de DevSecOps e precisam ser estendidas a todo código gerado por agentes de IA. Fazer isso manualmente é praticamente inviável; por isso, recomenda-se o uso de ferramentas de automação, como as disponíveis no Kaspersky Cloud Workload Security.
Proteção das comunicações entre agentes. Garanta autenticação mútua e criptografia em todos os canais de comunicação entre agentes. Utilize assinaturas digitais para verificar a integridade das mensagens.
Botões de emergência. Crie mecanismos para bloquear imediatamente agentes ou ferramentas específicas no momento em que um comportamento anômalo for detectado.
Uso de interfaces para calibração de confiança. Use indicadores visuais de risco e alertas de nível de confiança para reduzir o risco de as pessoas confiarem cegamente na IA.
Treinamento de usuários. Capacite sistematicamente os colaboradores sobre as realidades operacionais de sistemas baseados em IA. Utilize exemplos alinhados às funções reais de cada cargo para explicitar riscos específicos relacionados à IA. Dada a velocidade com que esse campo evolui, um treinamento anual de compliance não é suficiente; essas capacitações devem ser atualizadas várias vezes ao ano.
Para analistas de SOC, também recomendamos o curso Kaspersky Expert Training: Large Language Models Security, que aborda as principais ameaças aos LLMs e as estratégias defensivas para mitigá-las. O curso também é relevante para desenvolvedores e arquitetos de IA que atuam na implementação de LLMs.