Inteligência artificial e Machine Learning em segurança cibernética
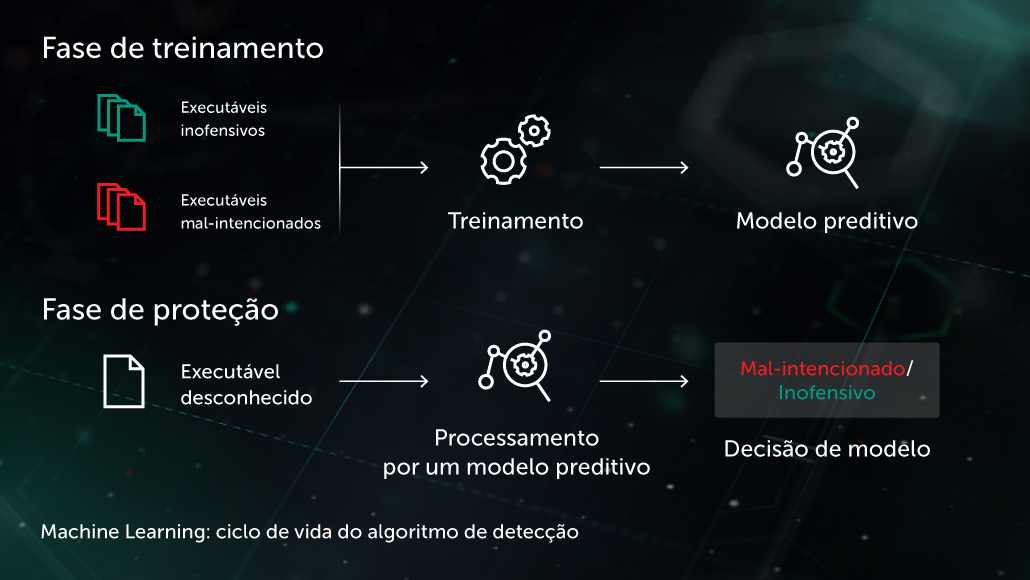
Arthur Samuel, um pioneiro em inteligência artificial, descreveu a IA como um conjunto de métodos e tecnologias que "confere aos computadores a capacidade de aprender sem serem explicitamente programados". Em um caso específico de aprendizado supervisionado para fins antimalware, a tarefa poderia ser formulada da seguinte maneira: dado um conjunto de recursos de objeto \( X \) e rótulos de objeto correspondentes \( Y \) como entrada, crie um modelo que produzirá os rótulos corretos \( Y' \) para objetos de teste não vistos anteriormente \( X' \). \( X \) poderia ser alguns recursos que representam o conteúdo ou comportamento do arquivo (estatísticas do arquivo, lista de funções de API usadas etc.) e os rótulos \( Y \) poderiam ser simplesmente "malware" ou "benigno" (em casos mais complexos, poderíamos ter uma classificação refinada, como vírus, Trojan-Downloader, Adware etc.). No caso da aprendizagem não supervisionada, estamos mais interessados em revelar a estrutura oculta dos dados, por exemplo, encontrar grupos de objetos semelhantes ou recursos altamente correlacionados.
A proteção da próxima geração em vários níveis da Kaspersky utiliza abordagens de IA, como Machine Learning, extensivamente em todos os estágios do pipeline de detecção: desde métodos de agrupamento escalonáveis usados para pré-processamento de fluxo de arquivos de entrada até modelos de rede neural profunda, robusta e compacta para detecção comportamental que trabalhará diretamente nas máquinas dos usuários. Essas tecnologias são projetadas para atender a vários requisitos importantes para aplicativos de segurança cibernética do mundo real, incluindo uma taxa extremamente baixa de falsos positivos, capacidade de interpretação de modelos e robustez contra adversários.
Vejamos algumas das mais importantes tecnologias baseadas em Machine Learning usadas nos produtos de endpoint da Kaspersky:
Conjunto de árvores de decisão
Nessa abordagem, o modelo preditivo assume a forma de um conjunto de árvores de decisão (por exemplo, uma floresta aleatória ou árvores com gradiente aumentado). Cada nó de uma árvore que não seja folha contém alguma questão relacionada às características de um arquivo, enquanto os nós folha contêm a decisão final da árvore sobre o objeto. Durante a fase de teste, o modelo percorre a árvore respondendo às perguntas nos nós com as características correspondentes do objeto em questão. No estágio final, as decisões de várias árvores são calculadas em uma maneira específica do algoritmo para fornecer uma decisão final sobre o objeto.
O modelo beneficia o estágio de proteção proativa pré-execução no local do endpoint. Uma de nossas aplicações dessa tecnologia é o Cloud ML for Android, usado na detecção de ameaça em dispositivos móveis.
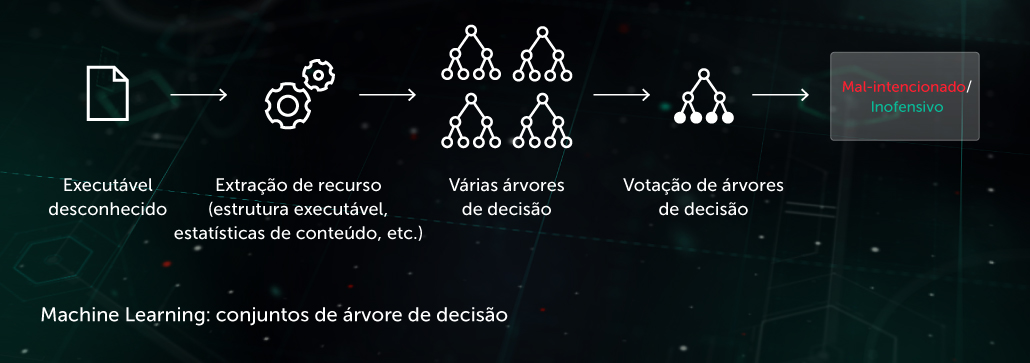
Hash de similaridade (hash sensível à localidade)
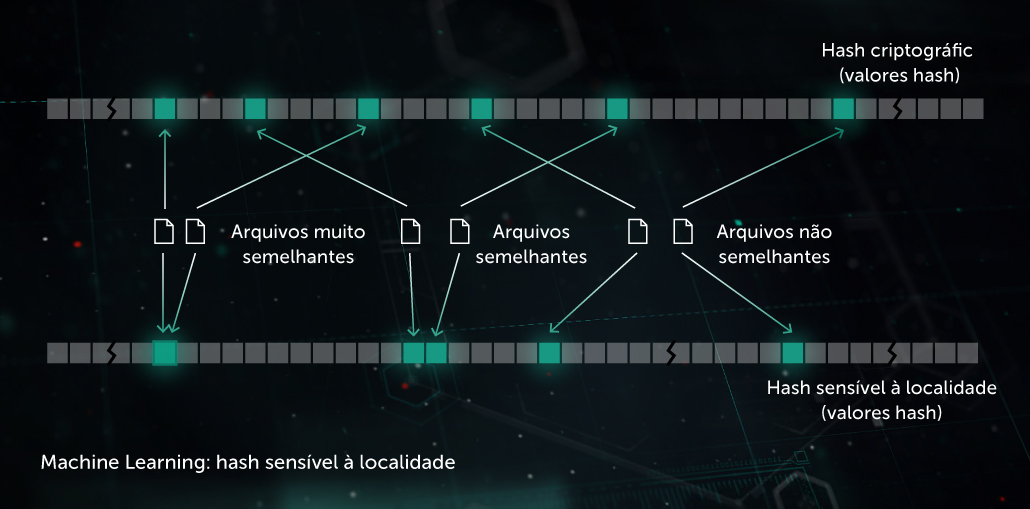
No passado, os hashes usados para criar "pegadas" de malware eram sensíveis a cada pequena alteração em um arquivo. Essa desvantagem era explorada por programadores de malware por meio de técnicas de ofuscação como o polimorfismo do lado do servidor: pequenas alterações no malware o retiravam do radar. O hash de similaridade (ou hash sensível à localidade) é um método de IA para detectar arquivos maliciosos semelhantes. Para fazer isso, o sistema extrai características do arquivo e usa o aprendizado de projeção ortogonal para escolher as características mais importantes. A compactação baseada em Machine Learning é então aplicada de modo que os vetores de valor de características semelhantes sejam transformados em padrões semelhantes ou idênticos. Esse método fornece uma boa generalização e reduz consideravelmente o tamanho da base de registros de detecção, uma vez que um registro agora pode detectar toda a família do malware polimórfico.
O modelo beneficia o estágio de proteção proativa pré-execução no local do endpoint. Ele é aplicado em nosso Sistema de detecção de hashes por similaridade.
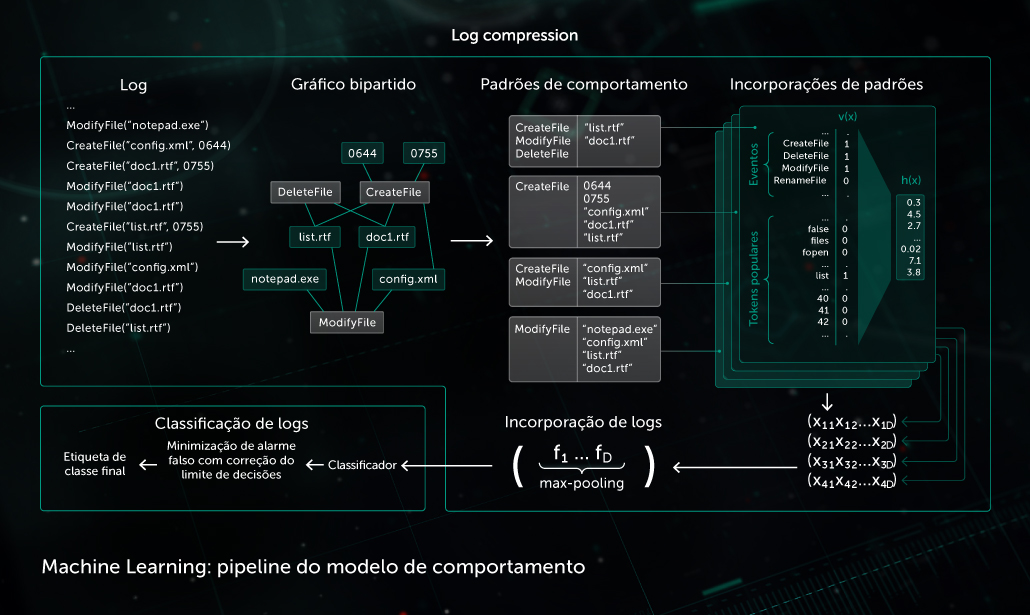
Modelo comportamental
Um componente de monitoramento fornece um log de comportamento, a sequência de eventos do sistema que ocorrem durante a execução do processo junto com os argumentos correspondentes. Para detectar atividades maliciosas em dados de logs observados, nosso modelo compacta a sequência de eventos obtida em um conjunto de vetores binários e treina a rede neural profunda para distinguir logs limpos e maliciosos.
A classificação do objeto feita pelo modelo comportamental é usada pelos módulos de detecção estática e dinâmica nos produtos Kaspersky no endpoint.
A IA também desempenha uma função igualmente importante na criação de uma infraestrutura adequada de processamento de malware em laboratório. A Kaspersky o usa para os seguintes fins de infraestrutura:
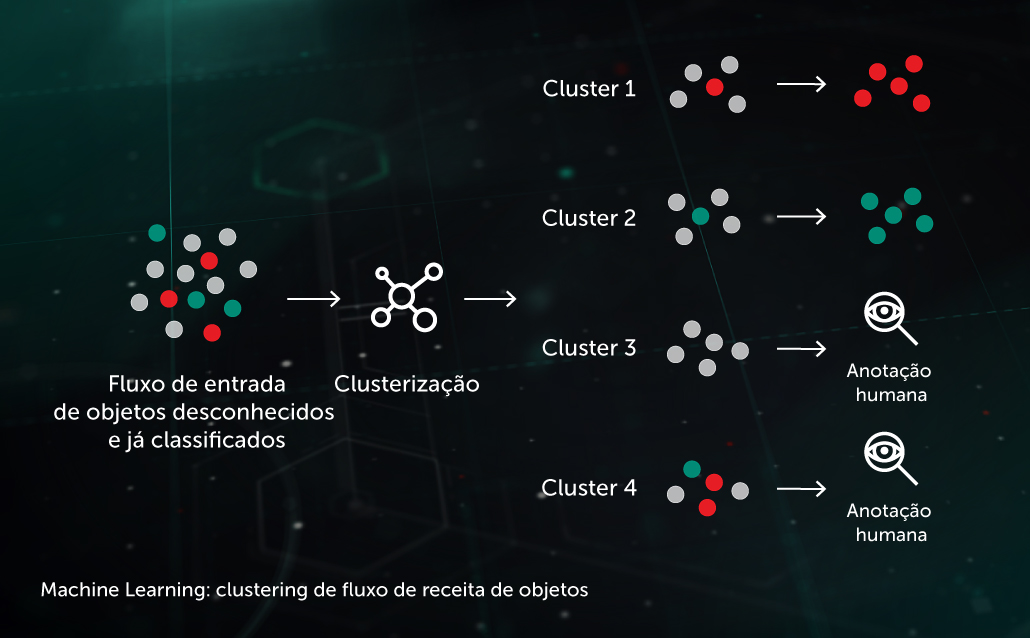
Clustering do fluxo de entrada
Os algoritmos de clustering baseados em Machine Learning nos permitem separar com eficiência os grandes volumes de arquivos desconhecidos que chegam à nossa infraestrutura em um número razoável de clusters, alguns dos quais podem ser processados automaticamente com base na presença de um objeto já anotado dentro dele.
Modelos de classificação em grande escala
Alguns dos modelos de classificação mais poderosos (como uma enorme floresta de decisão aleatória) requerem recursos significativos (tempo de processador, memória), juntamente com extratores de características caros (por exemplo, o processamento via sandbox pode ser necessário para logs de comportamento detalhados). É mais eficaz, portanto, manter e executar os modelos em um laboratório e, em seguida, destilar o conhecimento adquirido por esses modelos por meio do treinamento de algum modelo de classificação leve nas decisões de saída do modelo maior.
Segurança do Machine Learning
Os algoritmos de Machine Learning, uma vez liberados do laboratório para o mundo real, podem ser vulneráveis a muitas formas de ataque projetadas para forçar os sistemas de IA a cometer erros deliberados. Um invasor pode envenenar um conjunto de dados de treinamento ou fazer engenharia reversa do código do modelo. Além disso, os hackers podem usar modelos de Machine Learning de força bruta com a ajuda de sistemas de "IA adversária" desenvolvidos de forma especial, que podem gerar automaticamente muitas amostras de ataque e lançá-las contra a solução de proteção ou o modelo de Machine Learning extraído até que um ponto fraco do modelo seja descoberto. O impacto desses ataques em sistemas antimalware que usam a IA pode ser devastador. Um cavalo de Troia identificado incorretamente significa milhões de dispositivos infectados e milhões de dólares perdidos.
Por esse motivo, há algumas considerações importantes a serem aplicadas ao usar a IA em sistemas de segurança:
- O fornecedor de segurança deve compreender e atender cuidadosamente aos requisitos essenciais para o desempenho dos elementos de IA no mundo real e potencialmente hostil: requisitos que incluem robustez para adversários em potencial. As auditorias de segurança específicas de Machine Learning/AI e "red-teaming" devem ser componentes essenciais no desenvolvimento de sistemas de segurança que usam aspectos de IA.
- Ao avaliar a segurança de uma solução que usa elementos de IA, pergunte até que ponto a solução depende de dados e arquiteturas de terceiros, pois muitos ataques são baseados em informações de terceiros (estamos falando de feeds de inteligência contra ameaças, conjuntos de dados públicos, modelos de IA pré-treinados e terceirizados).
- Os métodos de Machine Learning/IA não devem ser vistos como uma solução milagrosa, eles precisam fazer parte de uma abordagem de segurança em várias camadas, em que as tecnologias de proteção complementares e o conhecimento humano trabalham juntos, protegendo-se mutuamente.
É importante reconhecer que, embora a Kaspersky tenha ampla experiência no uso eficiente de aspectos de IA, como Machine Learning e seu subconjunto de Deep Learning em suas soluções de segurança cibernética, essas tecnologias não são a verdadeira IA ou Inteligência Artificial Geral (AGI). Ainda há um longo caminho a ser percorrido até que as máquinas possam operar de forma independente e realizar a maioria das tarefas de forma totalmente autônoma. Até lá, quase todos os aspectos da IA na segurança cibernética exigirão a orientação e a experiência de profissionais humanos para desenvolver e refinar os sistemas, aumentando suas capacidades ao longo do tempo.
Para obter uma visão geral mais detalhada dos ataques populares a algoritmos de Machine Learning/IA e os métodos de proteção contra essas ameaças, consulte nosso whitepaper "IA sob ataque: como proteger a inteligência artificial em sistemas de segurança".





